With the 21st Century Cures Act Final Rule requiring support for the SMART and HL7 FHIR APIs in certified health IT, patients and other stakeholders are increasingly accessing healthcare data in standardized FHIR formats. However, there is very little tooling available to confirm or improve the quality and utility of the FHIR data being exported.
To address this, with funding from the Office of the National Coordinator of Health Information Technology/Assistant Secretary for Technology Policy (ONC/ASTP) and the Advanced Research Projects Agency for Health (ARPA-H), the SMART team is building CumulusQ, a set of open source tools to assess the character and quality of FHIR data.
CumulusQ computes detailed metrics from available FHIR data and provides interactive visualizations for users to review trends and identify issues in the data. Building on the metric definitions developed by the NIH All of Us initiative’s Qualifier project, it supports finding and remediating errors that have been introduced during data entry, mapping, serialization, or export, as well as determining if a data set is fit for purpose. The Qualifier metric set is aligned with the widely used the OHDSI Data Quality Dashboard and OHDSI OMOP Achilles metric sets, and is structured based on the guidelines outlined in the Kahn framework. The current version focuses on the USCDI v1 data elements as described in the FHIR US Core STU4 Implementation Guide (IG) and implemented by certified EHR systems. Metrics can also be customized or adapted to work with FHIR data that complies with other IGs.
An Open Source FHIR Native Framework
CumulusQ is unique in a few ways. Firstly, it’s the only fully open source FHIR data quality framework. The metric definitions, cloud implementation, local implementation, and the visualizations are all publicly maintained on GitHub. Secondly, the metrics are FHIR native, obviating the need for data conversion which can introduce errors, and taking advantage of definitions in the FHIR schemas when evaluating data types and required elements. Thirdly, CumulusQ incorporates data characterization, going beyond pass/fail metrics to enable users to measure whether a data set is fit for purpose. Fourthly, CumulusQ aligns with existing data quality and characterization metrics used at OMOP sites, providing familiarity to researchers and enabling comparisons between data sources. Finally, CumulusQ leverages scalable, off-the-shelf SQL engines and business intelligence tools rather than relying on custom code.
Built for Cumulus and other Bulk FHIR Projects
The CumulusQ software can be run at scale as an integrated process at sites participating in the Cumulus federated clinical network. In this setting, the metrics process data in each de-identified Cumulus cloud node, generating both site-specific and network-wide reports and visualizations viewable in the Cumulus network dashboard web app. Based on the results, analysts and researchers tailor project-specific data cleaning and transformation steps and make informed adjustments to analytic approaches.
For reviewing smaller bulk FHIR data sets, CumulusQ can also be run directly on locally available Bulk FHIR NDJSON files and will process and visualize the metrics without connecting to a cloud service.
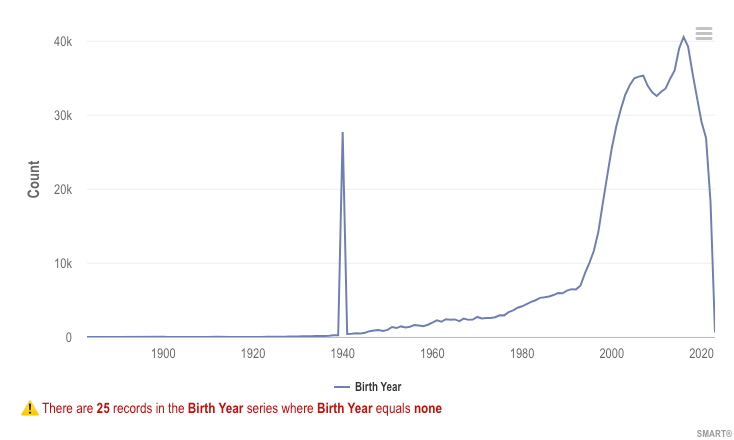
Example metric visualization characterizing Patient birth year:
Resources:
- CumulusQ metrics implementation
- CumulusQ local visualization tool
- Sync for Science Qualifier metric definitions
You must be logged in to post a comment.